Google DeepMind が Accelerating the frontiers of scientific discovery: Google’s $40M commitment to the Genesis Mission を発表 ── 科学発見を加速する4000万ドルのAIリソース提供
Googleが科学発見加速プロジェクト「Genesis Mission」に4000万ドルのAIリソースを提供。AlphaFold 3やAlphaEvolveなどの最先端モデルを研究者に公開。

Googleが科学発見加速プロジェクト「Genesis Mission」に4000万ドルのAIリソースを提供。AlphaFold 3やAlphaEvolveなどの最先端モデルを研究者に公開。
OpenAIがエンタープライズ向けAIエージェントプラットフォーム「OpenAI Presence」を発表。顧客対応や社内ワークフロー向けに、信頼性の高い音声・チャットエージェントのデプロイを可能にする。
OpenAIがエンタープライズ向けAIエージェントプラットフォーム「OpenAI Presence」を発表。信頼できる音声・チャットAIを社内外のワークフローに導入できる。
OpenAIとHugging FaceがAIモデル評価中のセキュリティインシデントに関する初期調査結果を共有。高度なサイバー能力と防御側が学ぶべき教訓に迫る。
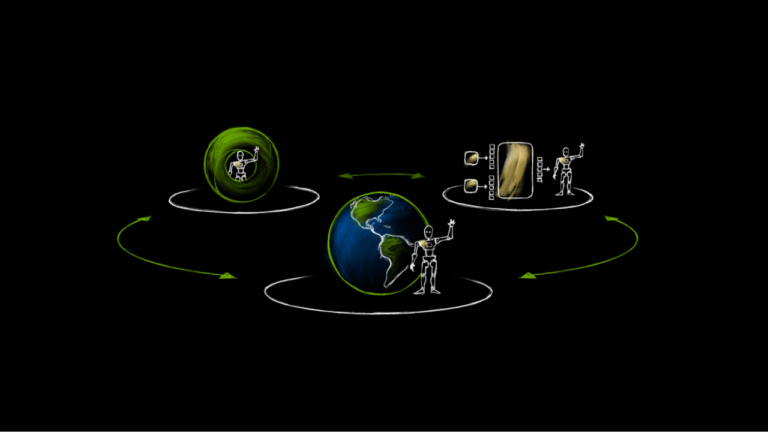
NVIDIAチームによる物理AI向けシミュレーションの最新動向レポート。3つのコンピューターパラダイムを通じて、ロボット開発のデータ不足をどう解決するかを徹底解説。

Google DeepMindがサイバーセキュリティ特化モデル「Gemini 3.5 Flash Cyber」を発表。軽量・高速モデルを活かし、低コストで脆弱性の発見と修正を爆速化する。

Google DeepMindがエージェント向けに最適化したGemini 3.6 Flashなどをリリース。出力トークンを大幅削減しつつ低価格化を実現。

ロボット学習の最大のネックはデータ不足。Hugging Faceが、ロボット不要で手持ちグリッパーから操作データを収集できるシステム「Grabette」をリリースした。
OpenAIが長時間稼働するAIモデルのデプロイから得た安全リスクや失敗例、改善策の知見を共有。次世代AIの安全性を考える上で必見の内容。

NVIDIAがエッジデバイス向けの40億パラメータ・ワールドモデル「Cosmos 3 Edge」を公開。15Hzのリアルタイム制御を実現。