Google DeepMind が Gemini 3.1 Flash-Lite をリリース ── 圧倒的なスピードと低コストで最強コスパ実現
Googleがまた新しいモデルを出しましたが、今回はコストパフォーマンスが尋常じゃないです。Gemini 3.1 Flash-Liteというモデルが登場しましたが、この爆速と激安価格設定は見逃せません。大量のリクエストを捌く必要がある開発者にとって、まさに待ち望んでいたモデルと言えるでしょう。
▸何が変わったのか
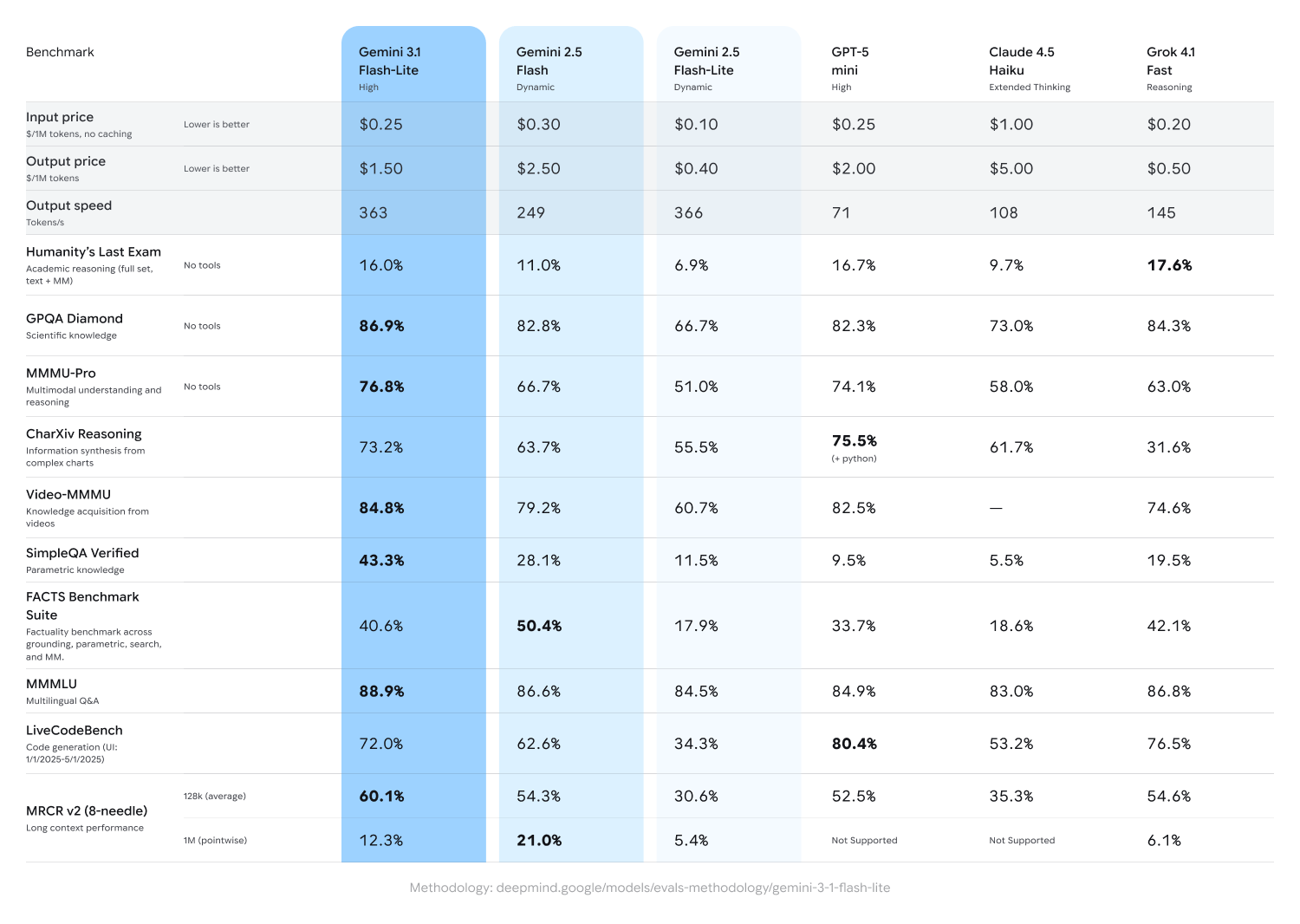
Gemini 3.1 Flash-Liteは、同シリーズ中最速かつ最もコスト効率の良いモデルとして登場しました。価格は入力が$0.25/1Mトークン、出力が$1.50/1Mトークンと、とにかく安いです。速度面では、前世代の2.5 Flashと比較して最初の応答までの時間が2.5倍高速化し、出力速度も45%向上しています。品質も妥協しておらず、Arena.aiのリーダーボードではEloスコア1432を記録。さらに「思考レベル(thinking levels)」機能が標準装備され、タスクに応じてモデルの「思考」の深さを調整できるようになりました。
◈前モデル / 競合との比較
前世代のGemini 2.5 Flashと比較して、応答速度は2.5倍、出力速度は45%向上しています。品質面でもGPQA Diamondで86.9%やMMMU Proで76.8%といったスコアを叩き出し、以前の大型モデルである2.5 Flashを凌駕する性能を発揮しています。


◈技術背景と意義
これまでの高性能モデルは高価で遅いのが悩みでしたが、このモデルは「大量の処理を安く、超高速で回す」ことに特化しています。特に「Time to First Answer」が2.5倍になっているのは大きな意味で、ユーザーが返答を待つストレスを劇的に減らせるため、チャットボットなどのリアルタイムアプリに最適です。安いのにGPQA Diamondで86.9%、MMMU Proで76.8%という高いスコアを出しており、単なる軽量版ではないのがすごいところですね。
▸こんな人・用途に
翻訳、コンテンツのモデレーション、ユーザーインターフェースの生成、シミュレーションの作成。
▸Redditの反応
Reddit上ではまだ話題になっていない様子で、スレッド自体も静かな感じ。唯一のコメントはmod運営にちょっと呆れつつ、過去のニュースを求めているみたいだ。
「2日前のニュースはある? 3月2日頃の投稿は見たけど、ここのmodは相変わらずだな…特に昨日の情報が知りたいんだけど。」
SOURCE: Google DeepMind (2026-03-03)