Hugging Face が Beyond Semantic Similarity: Introducing NVIDIA NeMo Retriever’s Generalizable Agentic Retrieval Pipeline をリリース ── 検索が「考える」時代の到来
検索技術といえば「意味の近いものを探す」のが当たり前だったけど、NVIDIAがその常識を覆しに来た。ViDoRe v3で堂々の1位、さらには推理力が求められるBRIGHTでも2位を獲得したこの新パイプラインは、まるで人間のように思考しながら情報を探し出す。これは単なる検索の進化ではなく、AIが自律的に「調査」をするための大きな一歩に感じた。
▸何が変わったのか
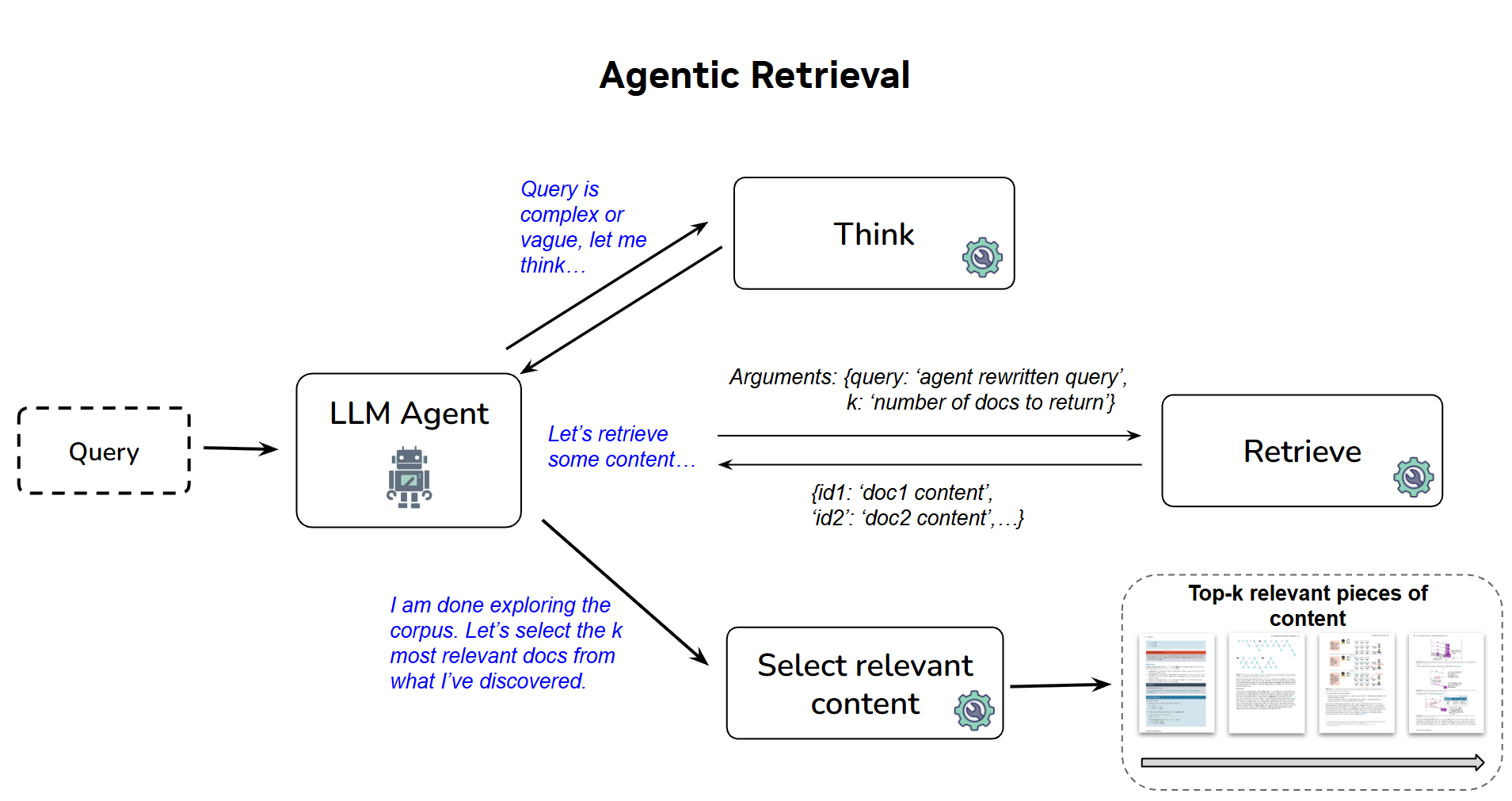
NVIDIA NeMo Retrieverチームが開発したこのパイプラインは、ViDoRe v3パイプラインリーダーボードで1位、推論を要するBRIGHTリーダーボードで2位を獲得している。従来の意味的類似度(Semantic Similarity)だけに頼らず、LLMと検索エンジンを反復的なループでつなぐ「Agentic Retrieval」を採用したのが大きな変化点だ。具体的にはReACTアーキテクチャに基づき、`think`で計画を立て、`retrieve (query, top_k)`でコーパスを探索し、`final_results`で最終的なドキュメントを出力する仕組みを導入。これにより、アーキテクチャを変更することなく、多様なベンチマークで最高峰のパフォーマンスを達成している。
◈前モデル / 競合との比較
従来主流だった「dense retrieval(密ベクトル検索)」はあくまで静的な類似度比較に過ぎず、複雑な推論には対応できなかった。対して本パイプラインは、特定のデータセットに過適合した専用ソリューションではなく、データに合わせて動的に戦略を適応させる「汎用性」を優先して設計されている点で大きく異なる。



◈技術背景と意義
これまでの検索は「キーワードや意味が合っていればOK」だったけど、今回はもっと深い。LLMは「考える」のは得意だけど膨大なデータを読むのが遅く、検索エンジンは「速い」けど考えるのが苦手。この技術は、両者を協力させて「質問を修正しながら必要な情報を見つけるまで探し続ける」エージェントのような仕組みを作っている。要するに、ただ検索するんじゃなくて、目的のために試行錯誤できるようになったってことだ。
▸こんな人・用途に
複雑なビジュアルレイアウトの解析が必要なドキュメント検索や、深い論理的推論が求められるエンタープライズ向けの検索システムに最適。完全に整備された単一分野のデータだけでなく、現実世界のように多種多様な課題が混ざり合うデータ環境での利用が想定されている。
◆入手方法・リンク
現時点ではOSS(オープンソース)ではなくクローズドソースとして提供されており、GitHubリポジトリ等のコード公開は情報なし。技術的な詳細やアーキテクチャについては、Hugging Face上の公式記事で公開されている。
SOURCE: Hugging Face (2026-03-13)



