Hugging Face 記事で AWS の基盤モデル学習・推論のビルディングブロックが解説 ── スケーリング法則は「1つ」から「3つ」の時代へ
基盤モデルのスケーリングって、もう「パラメータを増やせば性能が上がる」という単純な話じゃない。NVIDIAが言う「3つのスケーリング法則」──事前学習、ポストトレーニング、テスト時計算──がそれぞれ独立した最適化対象になっている。この記事は、その3つの要件がAWSインフラ上でどう収束していくのかを真面目に考察した良質な解説。
▸何が変わったのか
かつてスケーリングはKaplan et al. (2020)が示した「パラメータ数・データセットサイズ・学習計算量を増やせばロスが予測可能に下がる」という単一のパワーロー則で説明できた。しかし今やNVIDIAの定式化する「3つのスケーリング法則」へと拡張。つまり事前学習に加えて、ポストトレーニング(SFTやRLベースの手法)と、テスト時計算(「長い思考」や検索・検証・マルチサンプル戦略)でも性能がスケールする時代になった。この3つのスケーリング領域は、いずれも密結合のアクセラレータ計算、高帯域幅・低遅延ネットワーク、分散ストレージバックエンドという共通のインフラ要件に収束しつつある。



◈技術背景と意義
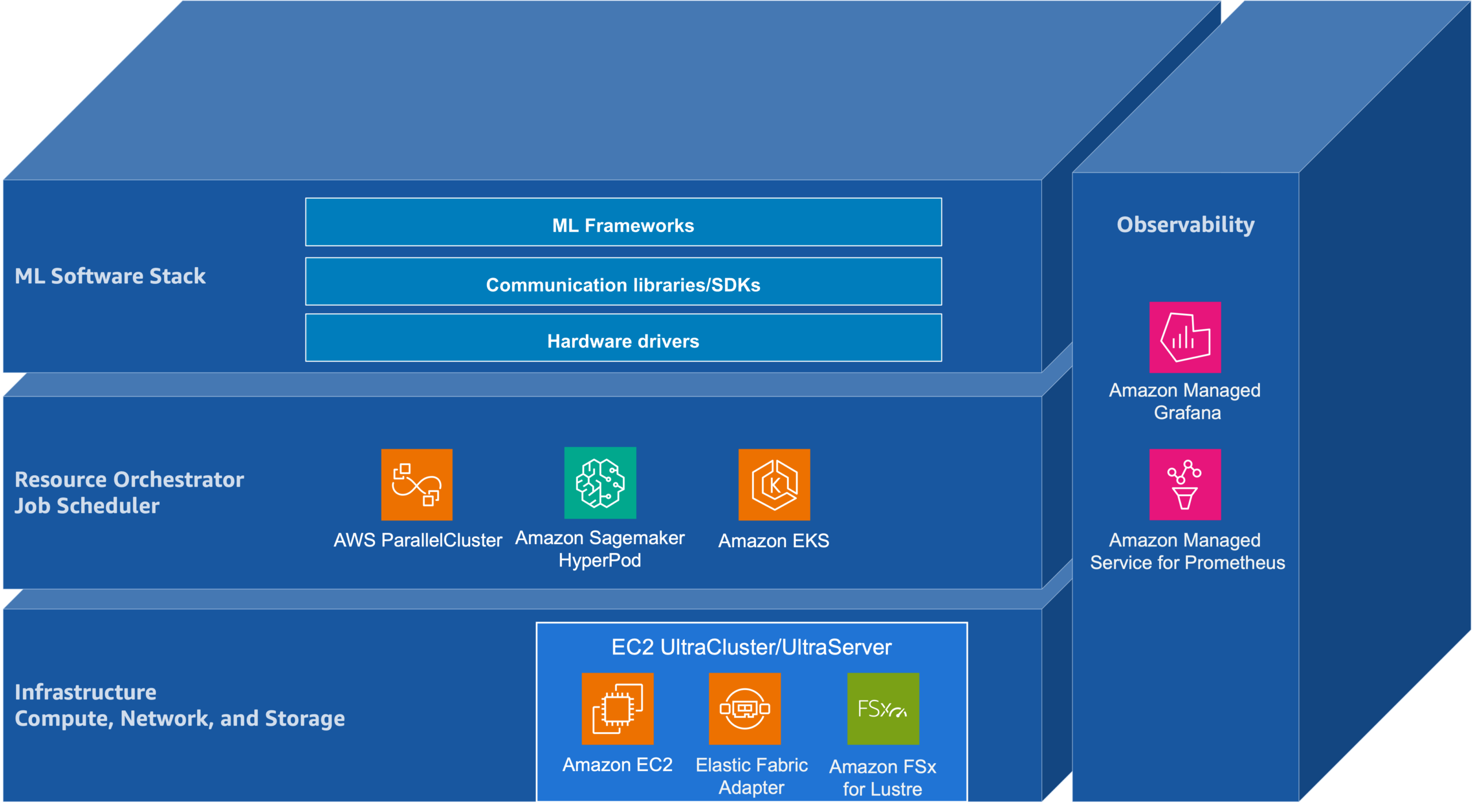
基盤モデルの開発は、事前学習・ポストトレーニング・推論という3つのフェーズに分かれている。従来は「事前学習に計算を注ぎ込めばOK」だったけど、今では学習後の微調整(SFTやRL)や、推論時に計算を多く使う手法(Chain-of-Thought的な「長い思考」など)でも性能が大きく向上する。記事ではOSSスタックの階層構造も図解している。クラスタ層でSlurmやKubernetesがリソース管理を行い、PyTorchやJAXが分散学習を担当し、PrometheusとGrafanaでオブザーバビリティを実現する、という王道の構成。
▸こんな人・用途に
AWS上で基盤モデルの学習・推論パイプラインを構築・運用している機械学習エンジニアや研究者。特にSlurm/Kubernetes + PyTorch/JAX + Prometheus/GrafanaのOSSスタックを使っているチームにとって、インフラ設計の指針として参考になる。
SOURCE: Hugging Face (2026-05-12)


