Hugging Face が ITBench-AA を公開 ── 最先端AIでも半分解けないエンタープライズIT実務ベンチマーク
LLMって万能に見えるけど、実際のエンタープライズIT現場で通用するのか。Artificial AnalysisとIBM Researchが作った新ベンチマーク「ITBench-AA」で検証した結果、どの最先端モデルも正答率50%に届かないという衝撃の結果が出た。
▸何が変わったのか
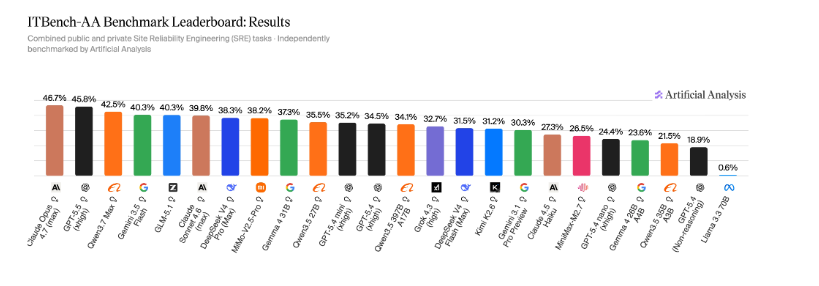
ITBench-AAは、エージェント型エンタープライズITタスクを評価する初のベンチマークシリーズ。第一弾としてSRE(Site Reliability Engineering)タスク59問を用意し、うち40問が公開、19問はホールドアウト。Kubernetesのインシデント対応を題材に、モデルはログやメトリクス、トレースを読み込み、根本原因となるエンティティを特定する。結果はClaude Opus 4.7が47%でトップ、続いてGPT-5.5が46%、Qwen3.7 Maxが42%。オープンウェイトではGLM-5.1が40%で最高。
◈前モデル / 競合との比較
同じエージェント系ベンチマークのTerminal-Benchと比べても、ITBench-AAは圧倒的に難易度が高い。またモデルごとにターン数が大きく異なり、GPT-5.5は平均31ターンで46%なのに対し、Gemini 3.1 Pro Previewは83ターンかけても30%。調査しすぎると誤検知が増えるという現象が起きている。DeepSeek V4 Proは38%、Gemma 4 31Bが37%と、小型モデルも健闘している。



◈技術背景と意義
SREタスクは、本番環境で動くKubernetesクラスタのトラブルシューティング。リソース枯渇、ロールアウト失敗、コネクションプール枯渇、ネットワーク分断など、実際のインフラで起きる障害を再現している。人間のSREエンジニアでも経験と勘が求められる仕事で、AIにはかなりハードルが高い。
▸こんな人・用途に
エンタープライズIT運用の自動化を検討しているインフラチーム、SREエンジニアの補助ツール開発者、エージェント型AIの実用性を評価したい研究者に参考になるベンチマーク。
SOURCE: Hugging Face (2026-05-27)