Hugging Face が Accelerating Transformers Fine-Tuning with NVIDIA NeMo AutoModel を紹介 ── たった1行でMoEモデルの学習が最大3.7倍高速化
最近の巨大なAIモデルには「Mixture-of-Experts (MoE)」という仕組みが欠かせないけど、学習時のメモリ消費や計算のオーバーヘッドがかなり厄介。そんななか、Hugging FaceのTransformers v5をベースにNVIDIAのNeMo AutoModelを組み合わせると、コードをほとんど変えずに学習速度が劇的に向上するらしい。これはMoEモデルをガッツリ触っている身からすると、めちゃくちゃ熱いアップデート。
▸何が変わったのか
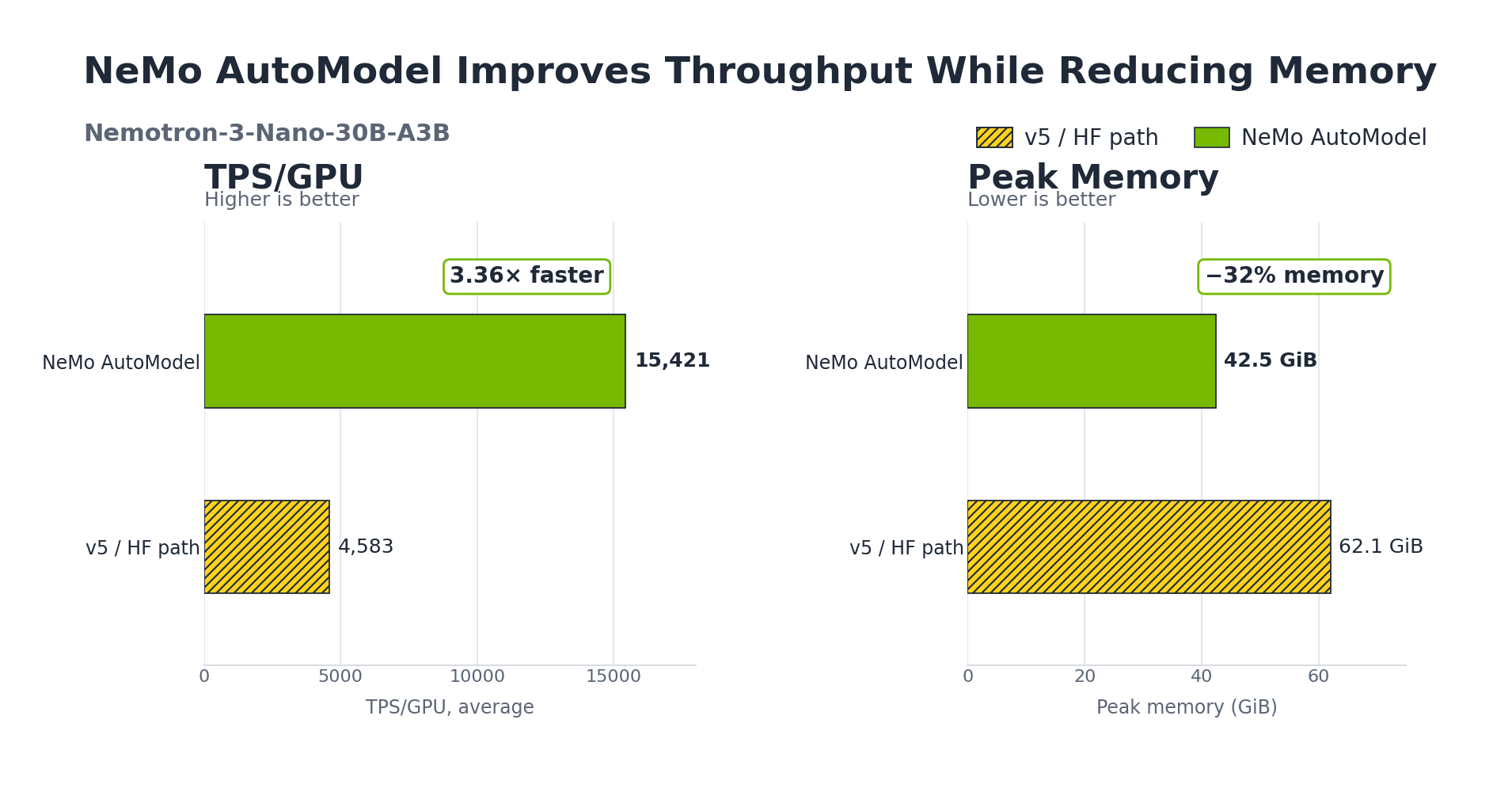
NVIDIAのNeMo AutoModelは、Transformers v5の上に構築されたライブラリ。Expert Parallelism (EP)、DeepEPのfused all-to-all dispatch、TransformerEngineカーネルという強力な最適化機能を追加している。実際のパフォーマンスがエグくて、ネイティブのTransformers v5と比較してMoEモデルのファインチューニング時に学習スループットが3.4〜3.7倍向上。さらにGPUメモリも29〜32%も削減される。驚くべきは、コードの変更が一切不要という点。NeMo AutoModelのインポートを1行足すだけで、いつもの`from_pretrained()` APIからそのまま呼び出せる手軽さだ。
◈前モデル / 競合との比較
従来のネイティブTransformers v5環境と比較して、学習スループットが3.4〜3.7倍高速化。さらにGPUメモリ使用量も29〜32%削減されている。出力されるチェックポイントは標準的なHF形式なので、推論ツール側の互換性も損なわない。



◈技術背景と意義
MoE(専門家モデルの混合)は、モデル内に複数の「専門家」を用意し、入力データに合わせて最適な専門家だけを動かすことで計算効率を上げる仕組み。ただし、どの専門家にデータを送るかというルーティング処理や、複数のGPUにまたがる通信が大きなネックになる。NeMo AutoModelが使うDeepEPは、この面倒なGPU間通信と実際の計算処理をうまくオーバーラップさせて待ち時間をなくす技術。これによって、巨大なMoEモデル特有のボトルネックが見事に解消されている。
▸こんな人・用途に
「NVIDIA Nemotron 3 Ultra 550B A55B」や「Qwen3-30B-A3B」のような大規模MoEモデルを、限られたGPUリソースでファインチューニングしたいエンジニアや企業。また、学習後のモデルをvLLMやSGLangなどの推論ツールでそのまま読み込ませたい場合にも最適。
◆入手方法・リンク
本記事の執筆時点では専用のGitHubリポジトリは公開されていない。詳細な実装方法やコードについては、Hugging Face公式ブログの技術記事を直接参照する必要がある。
SOURCE: Hugging Face (2026-06-24)




