Google DeepMind が Gemma 4 12B をリリース ── エンコーダーレスの統合アーキテクチャ、16GBメモリで動くマルチモーダル
Google DeepMindから、ノートPCでガッツリ動く新しいマルチモーダルモデル「Gemma 4 12B」が登場。これまでのマルチモーダルにつきものだったエンコーダーを完全に無くし、視覚と音声を直接処理する仕組みはかなりエモい。手元の16GBメモリ環境で高度な推論までこなせるというのだから、これはローカル勢として震えるアップデートだ。
▸何が変わったのか
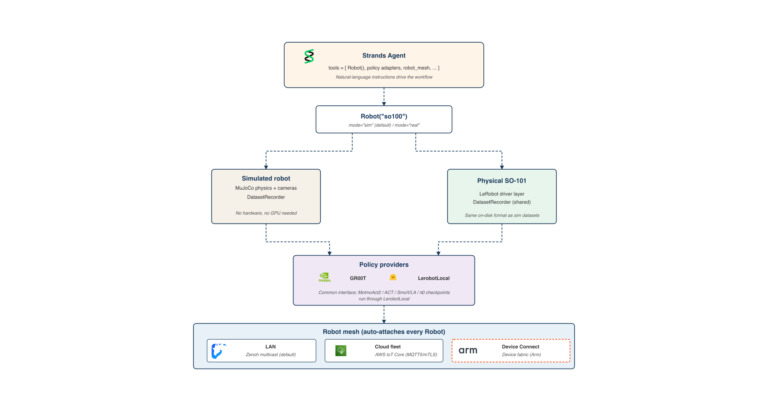
最大のトピックは、マルチモーダル処理にありがちな別々のエンコーダーを排除した「エンコーダーフリーアーキテクチャ」を採用した点。画像や音声を別個に変換する手間が省かれ、遅延やメモリ消費を大幅にカットしている。しかも、初のミッドサイズモデルとして「ネイティブオーディオ入力」に対応。26BのMixture of Experts (MoE)モデルに迫る推論性能を持ちながら、VRAM 16GB(またはユニファイドメモリ16GB)でローカル実行が可能だ。さらに、推論レイテンシを減らす「Multi-Token Prediction (MTP) drafters」も標準搭載している。
◈前モデル / 競合との比較
エッジ向けの「E4B」と、より高度な「26B MoE」の間を埋めるミッドレンジの位置づけ。26Bモデルに肉薄するベンチマークスコアを叩き出しつつ、総メモリフットプリントはその半分以下に収まっている。また、Gemma 4シリーズ全体で1億5000万ダウンロードを突破しているだけに、コミュニティの期待度もかなり高い。



◈技術背景と意義
従来のAIモデルは、画像や音声を言葉として理解させるために「エンコーダー」という通訳機を別途用意していた。これがメモリを食うし、処理の遅れにもつながっていたんだ。今回の仕組みなら、通訳を介さずに視覚と音声の情報を直接LLMのバックボーンに流し込める。これにより、普通のノートPCでもサクサクと高度な認識やエージェント的な動作ができるというワケ。Apache 2.0ライセンスで提供されているのも嬉しい限りだ。
▸こんな人・用途に
– 16GBメモリの一般的なノートPCで、高度なマルチモーダル処理やエージェントワークフローを構築したいローカルAI開発者
– 遅延を嫌うリアルタイム処理が必要な、ウェアラブルロボットアームやエンタープライズ向けAIセキュリティ用途
– 視覚・音声を統合的に扱うプロトタイプを、手軽な環境でサクッと試したいクリエイター
SOURCE: Google DeepMind (2026-06-09)